Photon – Incredibly Fast Web Crawler

Introduction
Photon is lightning fast web crawler, designed for recon, which extracts URLs, files, intel & endpoints from a target. It has a Ninja Mode, so you can use over 100 threads and everything will go smoothly.

Photon: Lightning Fast Web Crawler
Photon is very flexible web crawler with various options that allows you to control timeout, delay, add seeds, exclude URLs matching a regex pattern, etc. This extensive range of Photon options gives you freedom to crawl a web as you wish.
In addition, it has a smart thread management and refined logic that gives you high performance. Even besides this, it’s not all that Photon can offer you. You can jump in Ninja Mode (--ninja), and to feel real speed boost, because you’ll have for clients making requests to the same server simultaneously. So, you don’t have to worry about slow connection.
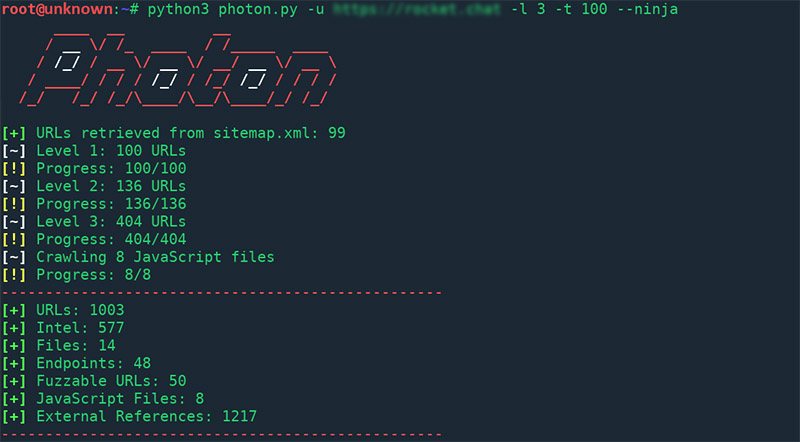
Features (data extraction):
- URLs: in-scope & out-of-scope,
- URLs with parameters.
- Intel: emails, social media accounts, amazon buckets, etc.
- Files: pdf, png, xml, etc.
- Secret keys: auth/API keys & hashes,
- JavaScript files & Endpoints present in them
- Strings matching custom regex pattern
- Subdomains & DNS related data
Plugins:
Supported Platforms:
- Linux (Arch, Debian, Ubuntu), Termux, Windows, Mac
Compatibility & Dependencies
Photon is compatible with python 2.x - 3.x. Beside standard python libraries, which comes preinstalled with a python interpreter, Photon requires:
- requests
- urllib3
- argparse
Install
You can launch Photon using a lightweight Python-Alpine (103MB) Docker image:
$ git clone https://github.com/s0md3v/Photon.git
$ cd Photon
$ docker build -t photon
$ docker run -it --name photon photon:latest -u google.com
To view results you head over to the local docker volume, just run:
$ docker inspect photon
or by mounting the target loot folder:
$ docker run -it --name photon -v "$PWD:/Photon/google.com" -u google.com
If you want to install it as a library, just do as follows:
$ pip install photon --user
Update
Photon is under heavy development and updates are frequent and regular. To check for updates, simply type --update.
Usage
usage: photon.py [options] -u --url root url -l --level levels to crawl -t --threads number of threads -d --delay delay between requests -c --cookie cookie -r --regex regex pattern -s --seeds additional seed urls -e --export export formatted result -o --output specify output directory -v --verbose verbose output --keys extract secret keys --exclude exclude urls by regex --stdout print a variable to stdout --timeout http requests timeout --ninja ninja mode --update update photon --dns enumerate subdomains & dns data --only-urls only extract urls --wayback Use URLs from archive.org as seeds --user-agent specify user-agent(s)\
To crawl a single website, simply type -u or --url:
$ python photon.py -u "http://example.com"




